Foundations
Foundations
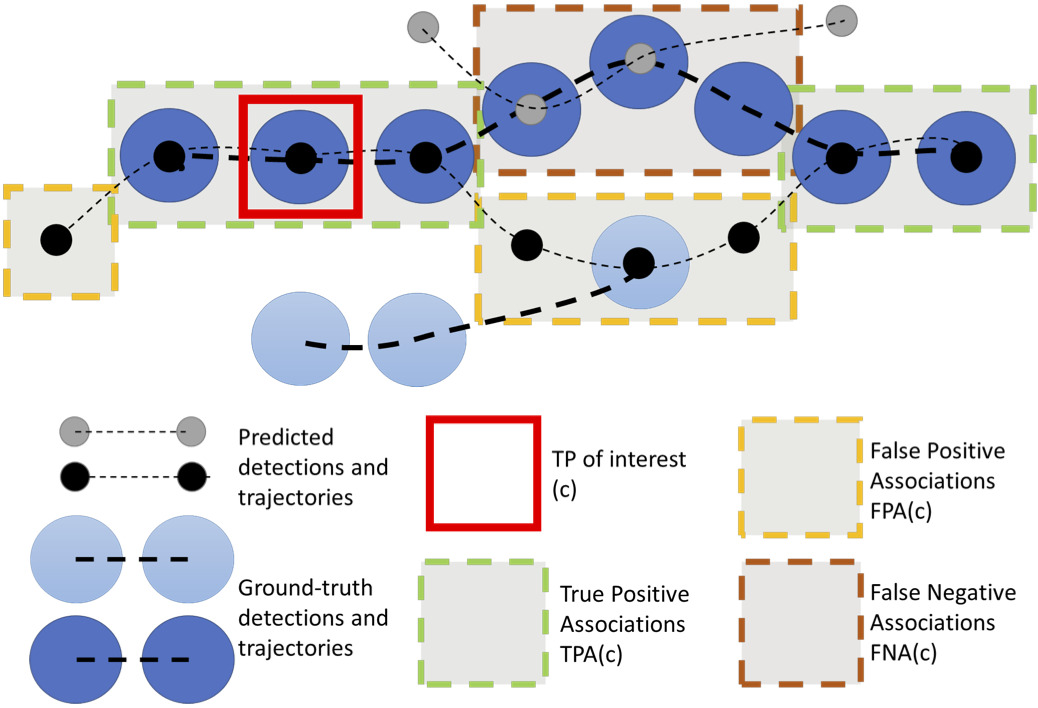
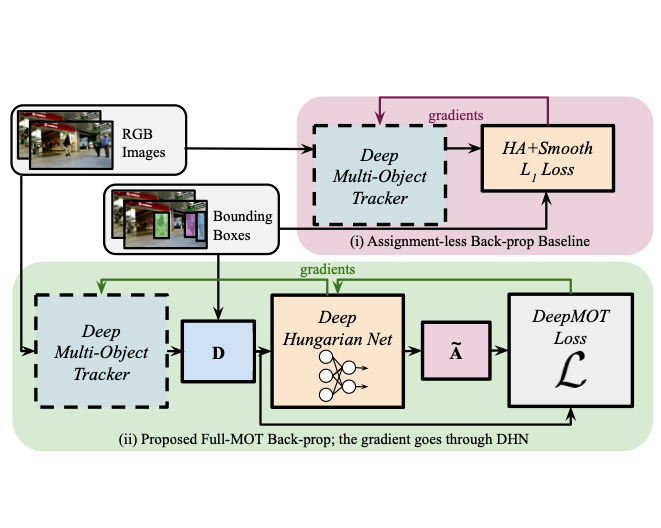
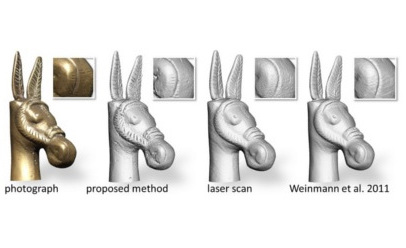
Built the groundwork for camera-based 4D scene understanding during my PhD at RWTH Aachen — joint geometry & pose estimation and any-object tracking/discovery. Co-authored HOTA, the standard tracking evaluation metric.
Relevant Papers: Foundations
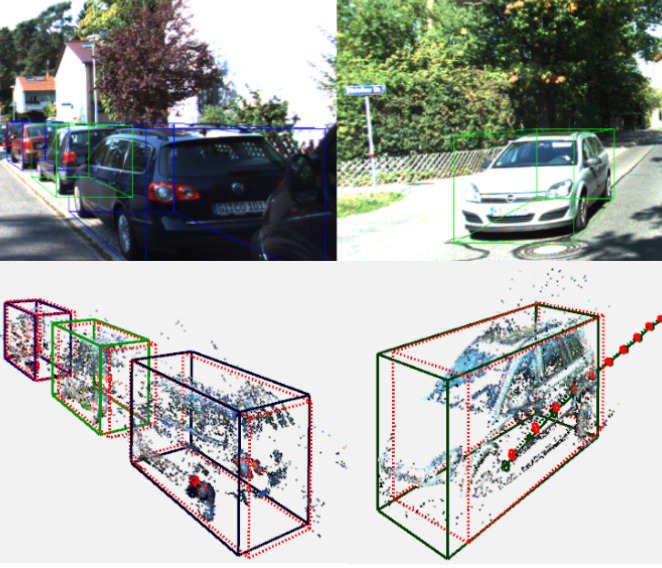
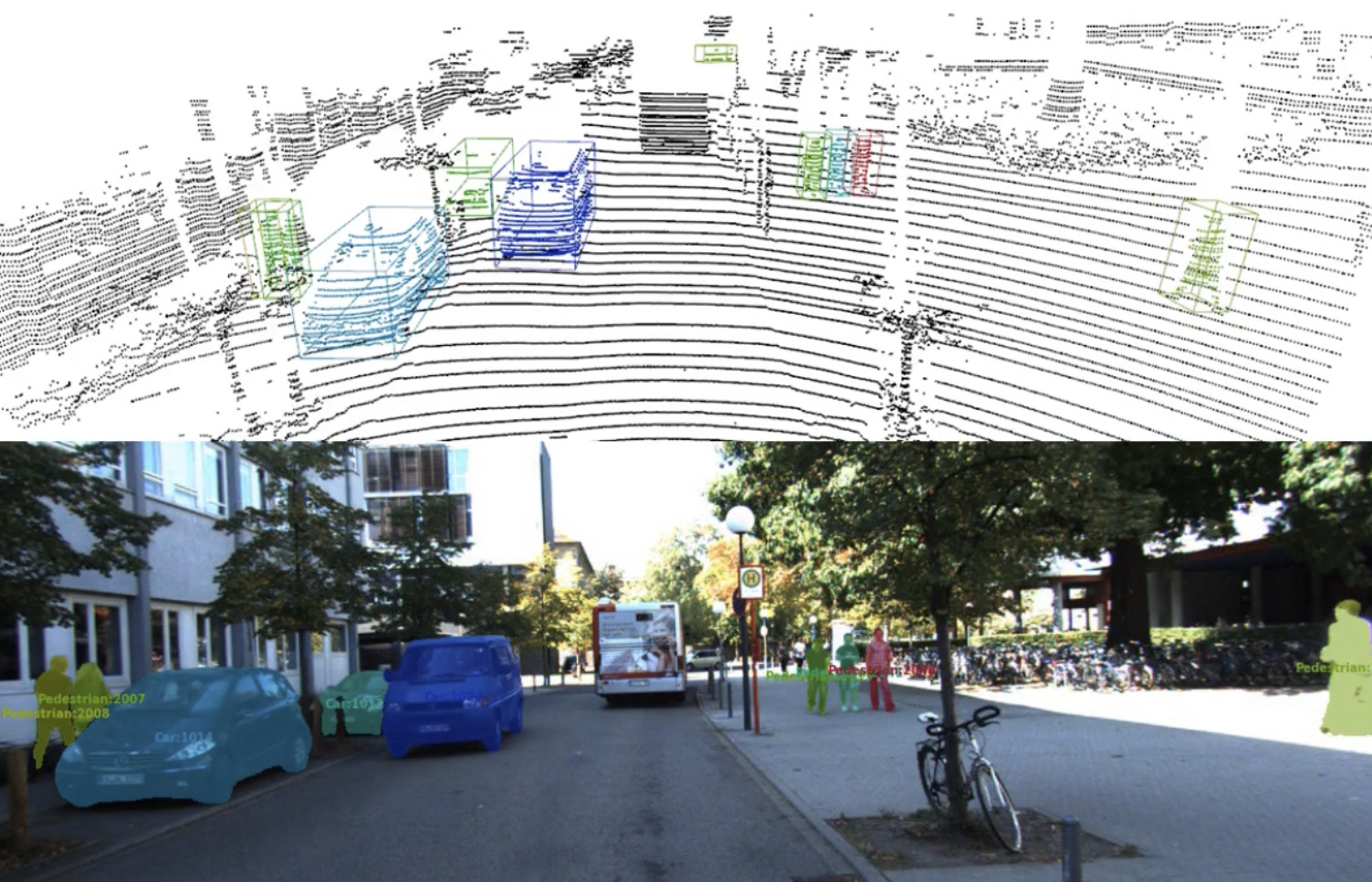
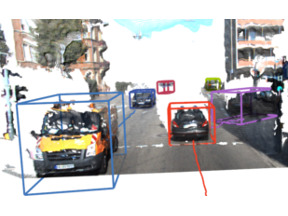
- Combined Image- and World-Space Tracking in Traffic Scenes (ICRA 2017)
- CAMOT — Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking (ICRA 2018)
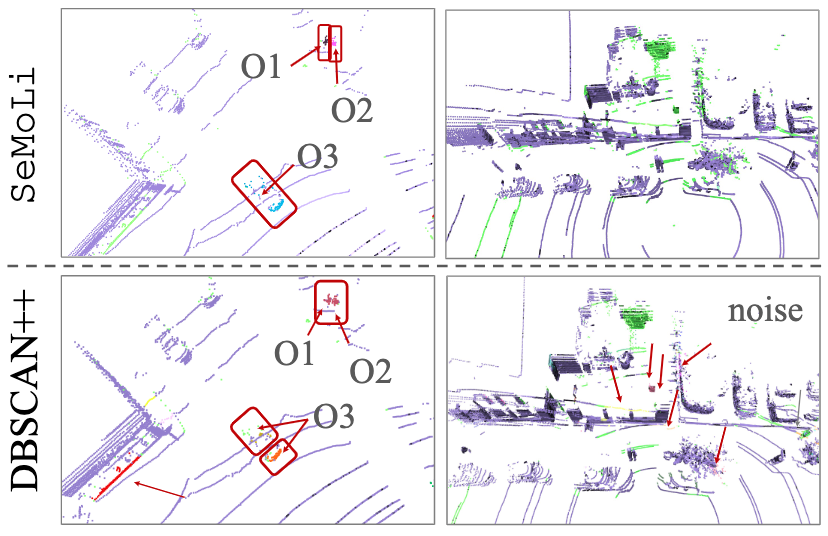
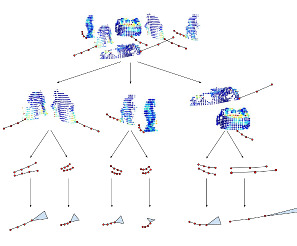
- Large-Scale Object Mining for Object Discovery from Unlabeled Video (ICRA 2019)
- 4D Generic Video Object Proposals (ICRA 2020)
- Opening up Open-World Tracking (CVPR 2022, oral)
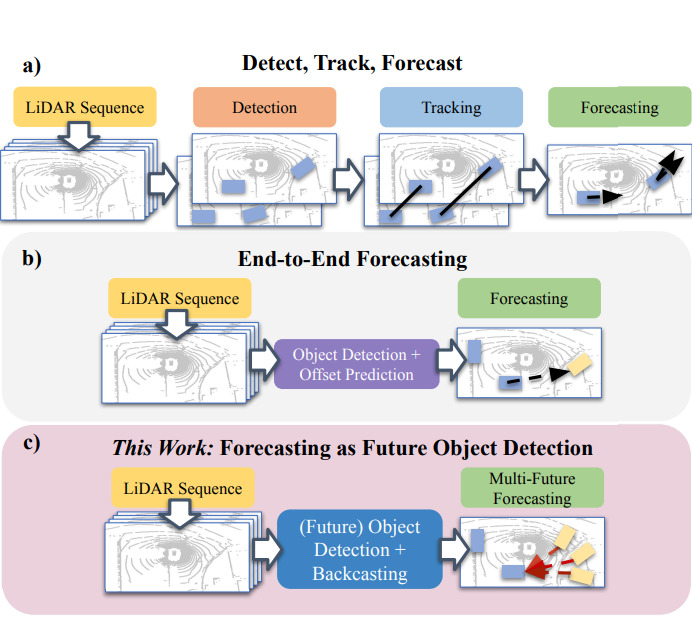
- Learning to Discover and Detect Objects (NeurIPS 2022)
 Industry
Industry
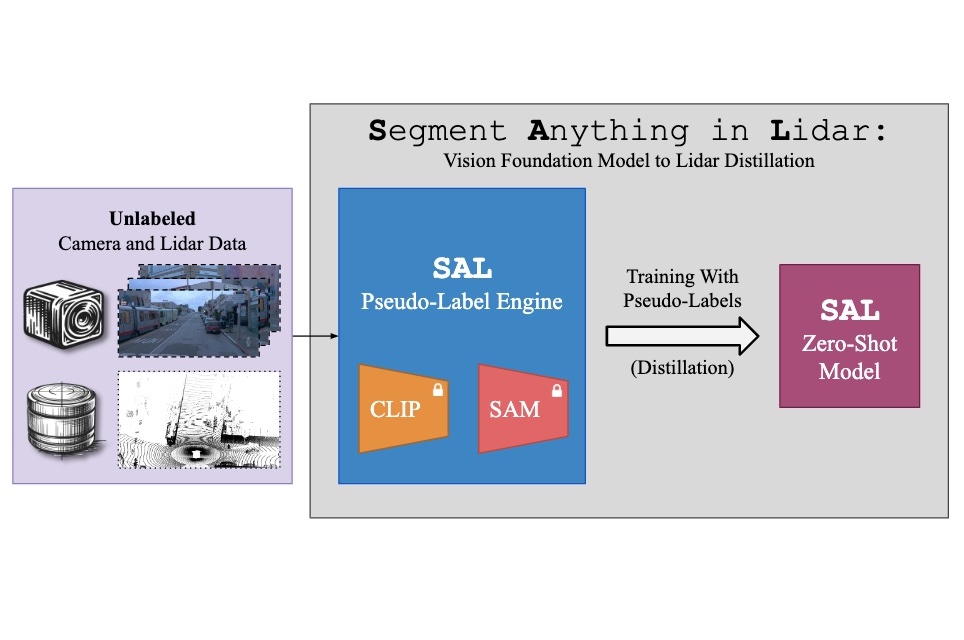
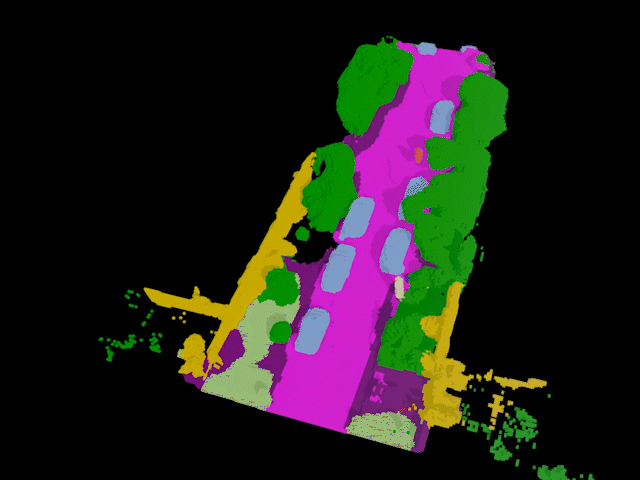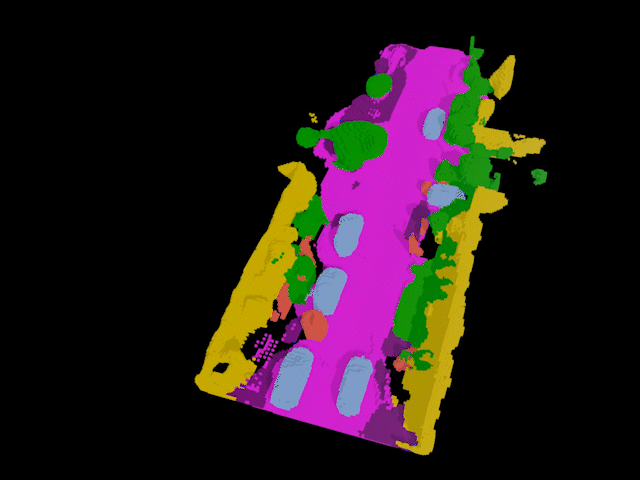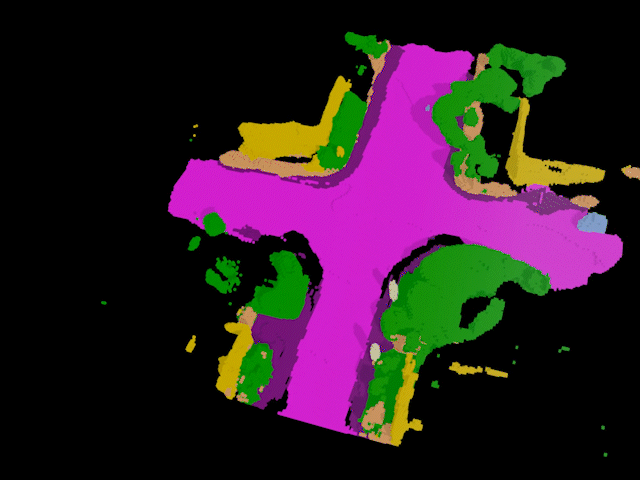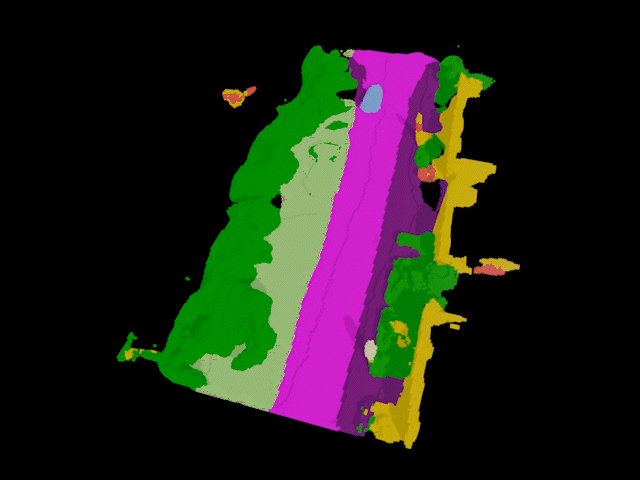
Building on prior work on tracking and reconstructing any object, I started & led the SAL project (open-vocabulary 4D localization & completion), powering auto-labeling for AV perception (featured at NVIDIA GTC 2024).
 Frontier
Frontier
The next frontier is memory: agents that operate over a lifetime in physical world. Laid out in my research statement, recently advanced in context of 3D reconstruction and structured sparse attention for world modelling.
Selected Papers
X. Wu, S. Elflein, J. Lucas, O. Russakovsky, L. Leal-Taixé, D. Paschalidou, J. Lorraine, A. Ošep: WorldTrace: Addressable Memory for Video World Models, Preprint, 2026. paper page
S. Elflein, R. Li, S. Agostinho, Ž. Gojčič, L. Leal-Taixé, A. Ošep: VGG-T3: Offline Feed-Forward 3D Reconstruction at Scale, CVPR, 2026. paper page
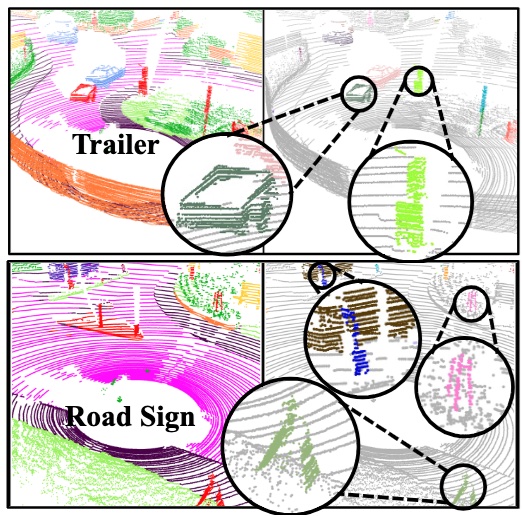
A. Ošep, T. Meinhardt, F. Ferroni, N. Peri, D. Ramanan, L. Leal-Taixe: Better Call SAL: Towards Learning to Segment Anything in Lidar, ECCV, 2024. paper video page